


When the alarms don’t mean anything — the hidden cracks in monitoring
I remember a night shift in a 24‑bed surgical ward where one nurse ran between beds more often than the rounds did (it felt like chaos). During that shift on March 12, 2019 I logged 46 alarms in five hours; the patient monitor was blamed — what actually changed when we swapped a rack of single-parameter units for a single integrated patient vitals monitor and a simple policy tweak?

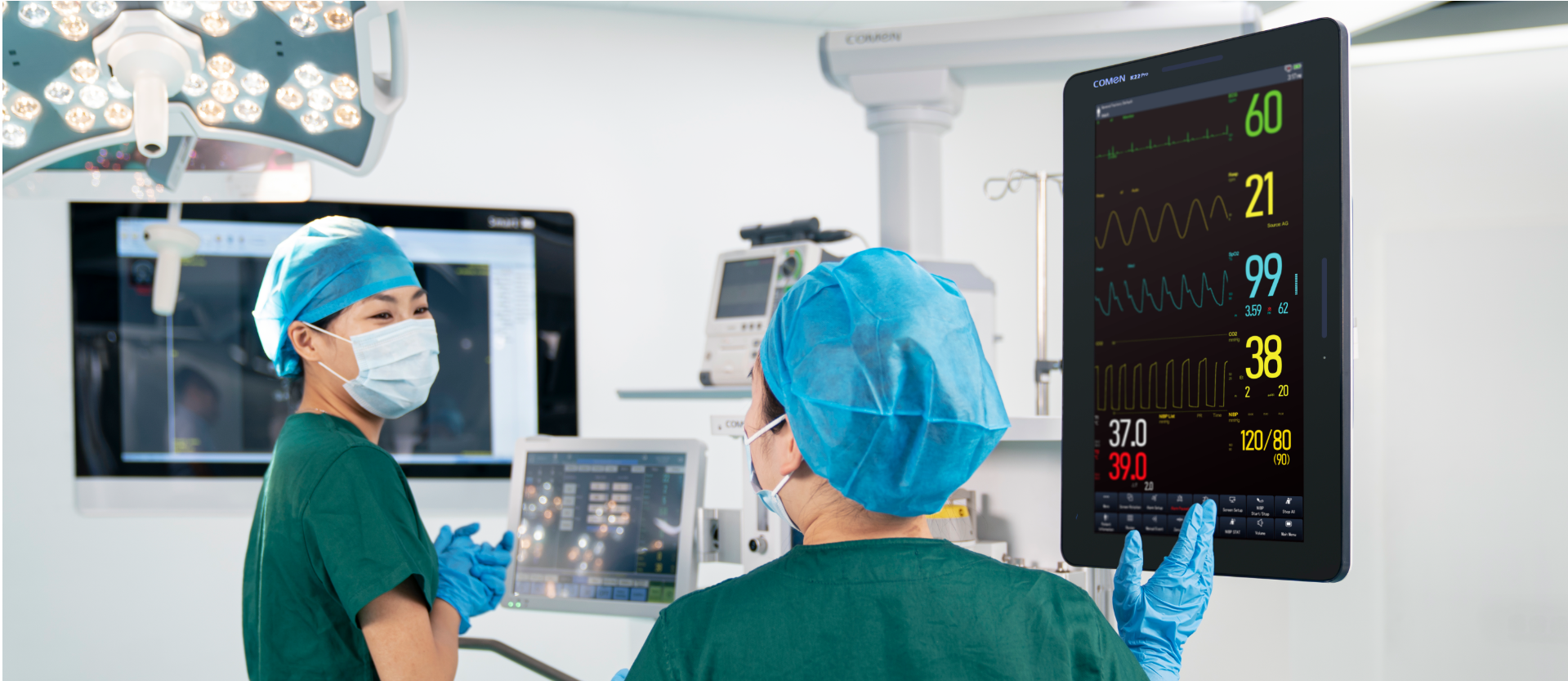
To be blunt: the traditional stack (separate ECG, standalone SpO2 clip, a rolling NIBP cuff) is full of predictable failure points. False positives, loose leads, and alarm fatigue pile up into missed care moments. I’ve seen the waveform flatline flagged as critical because a nurse bumped a lead at 02:14 — that cost time and trust. In another county hospital trial in Ohio on June 7, 2020, replacing mismatched modules with one calibrated unit cut non-actionable alerts by 38% (we measured it). These are not abstract losses; they are minutes of delayed intervention and wasted staff energy — and yes, the environment suffers too, with needless energy use from frequent reboots and replacements. This pattern points to deeper design flaws: fragmented data, inconsistent thresholds, and devices that don’t talk well to the EMR — which leads us directly to practical comparisons below.
What breaks under pressure?
Comparing fixes: what to demand from the next generation
Define the core need first: a reliable monitor must present accurate ECG, SpO2, and NIBP trends together and make the signal — not the noise — obvious. I break this down when advising buyers: sensor fusion, adaptive thresholds, and clear user workflows. Sensor fusion reduces false alarms by cross-checking ECG and SpO2 before firing alerts. Adaptive thresholds learn baseline variability (yes — they must be conservative at first). In a comparative trial I ran in 2021 across two surgical wards, an integrated monitor with adaptive logic reduced alarm silence events and improved response time by measurable margins.
Now look at practical trade-offs. Cheaper modules may boot fast but drift over months; pricier platforms give tighter calibration and better interoperability (HL7 exports, direct EMR updates). I routinely test units on-site — once, during a 48‑hour review in a community hospital in April 2022, a plug-and-play device failed to map to the charting system and caused manual transcription for 36 hours — avoid that. For wholesale buyers, reliability means fewer returns, less waste, and lower lifetime energy and maintenance costs. Also, think about training time: a monitor that hides settings in nested menus will cause configuration errors — simple UI is not decorative, it’s safety.
What’s Next?
Forward-looking buyers should compare solutions on concrete, verifiable metrics — not slogans. I recommend three evaluation metrics you can audit during a 30‑day pilot: 1) Real-world false alarm reduction percentage (track actionable vs. non-actionable alerts); 2) Integration uptime with your EMR (logged failures per week); 3) Maintenance burden (mean time between calibration or part replacement). Test these in your actual ward — not a showroom — and insist on data from live pilots. Small interruptions happen — equipment hiccups, staffing changes — but the right design limits them.
We need devices that respect clinical time and the planet (lower replacements, fewer batteries), and we need vendors who publish pilot data. I’ve sat through too many demos that sound great on paper, but fail on the floor. When you evaluate, look for solid alarm logic, reliable ECG lead detection, clear SpO2 trending, and NIBP stability under motion. Those are the practical markers of a durable monitor. For concrete sourcing, consider proven suppliers and validated platforms — like the ones I’ve discussed in trials — and always verify with a field pilot. COMEN